Continuing article series on Elasticsearch this article explains things around indices.
Creating an index
Grab your favorite REST tool and let’s and make sure you can access your cluster via rest if you like to execute these examples.
with HTTP PUT on /article-11-17 we will create index with name article-11-17 pretty convenient.
PUT /article-11-17
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2,
"refresh_interval": "5s",
"priority": "10"
}
}
}Hereunder the settings.index we define some important properties:
number_of_shards- the number of primary shards. Default is 5. Static setting.number_of_replicas- teh number of replica shards. Default is 1refresh_interval- default is1spriority- Unallocated shards are recovered in order of priority, whenever possible. Indices are sorted into priority order as follows:- the optional index.priority setting
- the index creation date
- the index name
These settings are frequently used and they can have a significant impact on the performance of your index and cluster.
Static and dynamic settings
- static settings can only be set at index creation time or on a closed index. There are not many static settings and the most important one is
number_of_shards. - dynamic settings can be changed on a live index using the update-index-settings API. E.g.:
PUT /article-11-17
{
"index" : {
"number_of_replicas" : 3
}
}Number of shards & things to consider
The question regarding a number of primary shards and replicas is probably the most important one. But there is no simple answer because the answer depends on things like query patterns, number of nodes in the cluster, the overall number of documents in the index.
- Every shard is a
Lucene index. A Lucene Index is a very efficient “search engine” - So many too small shard potentially produce too much overhead.
- Knowing that the question should be: when is the shard too big?
- You can query several indices at once, consider this by planing the shape of the indices.
- For example if your Logstash creates a daily index, that has 5 shards. Then with 7 days, you end up with 35 primary shards. If you search back for 7 days potentially 35 shards are participating in your query.
- If you expect few documents in the index, let say less than 3 million - it’s fine to have only one shard per index.
- Depending on node count (and space) you could experiment with a number of replicas, to increase search speed and throughput.
- The only problem that might arise here, is that indexing performance would be limited to one node because indexing is always happening to primary shards. If you have only one shard index all writes go to one node, holding that shard.
- I would say that 5 million of docs per shard is a good size to plan with. But you might also not notice any drop in performance with 30 million per shard as well. There is never one size fit’s all.
- Replicas may help with throughput. Consider 2 shards and replicas, on 4 nodes, ES will distribute them like in the picture below. In this case, parallel queries on the same index would probably utilize all 4 nodes, also reading from replicas.
An index with two primary shards and one replica can scale out across four nodes
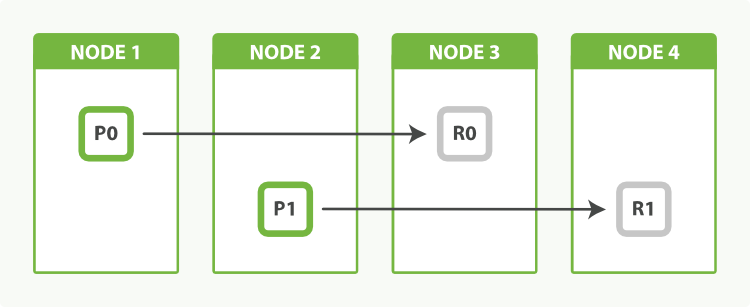 (Picture from Elasticsearch: The Definitive Guide [2.x])
(Picture from Elasticsearch: The Definitive Guide [2.x])
- One of the advanced optimization to be mentioned here is the possibility to define which nodes of the cluster shard of the index should be created. This makes sense in heterogeneous clusters that differ in Reduce Configuration. For example SSD machines v.s. large HDDs. or machines in particular Rack or DC. Detail can be found in the Documentation under Shard allocation Filtering.
Refresh interval
refresh_interval - is very important on heavy indexing. In many cases, you don’t need the result of the index to be visible immediately (e.g. logs index), but making refresh every second, might strongly affect the overall performance of the cluster. So you can go with 5s or 30s in such a case.
Reindexing
Once an index created with an unlucky number of primary shards you cannot change it on the existing Index. However, Elasticsearch provides very helpful Reindex API, that allows you “re-index” any documents of any existing indexes (even from remote clusters) to the new index. Here an example of reindexing of a Subset of Documents from articles-11-17 to a acricles_experiment index:
{
"source": {
"index": ["articles-11-17"],
"query": {
"bool" : {
"must": [
{ "range" : { "timestamp" : { "gte": "10.11.2017", "lte": "17.11.2017", "format": "dd.MM.yyyy" } } }
]
}
}
},
"dest": {
"index": "acricles_experiment"
}
}Outlook
Next, i want to spend some words on Document type mappings and things like Index templates